

We’ve been vocal about how essential it is for AI companies to respect the interests and intellectual property of content creators and for them to create a systematic way for you to opt in to the use of your content to train AI, including mechanisms to negotiate appropriate compensation if that’s what you want.
While we’re far from the “opt in” model creators deserve, there are a few ways to publicly reinforce your boundaries at the moment:
- Update your Terms of Service and add a “no AI” robots meta tag[link] on your site(s). Here’s how.
- Recently, OpenAI also provided documentation on how you can instruct its crawler, GPTBot, not to access your site, and by extension, not to use it for training its future models.
In this post, we’ll walk you through the current pros and cons of preventing GPTBot from crawling your site.
Should you disallow GPTBot?
Based on our current investigation, for now we recommend that sites explicitly disallow GPTBot in their robots.txt files to reinforce their intent to protect their rights.
To be clear, this step is not even close to a full solution to the problem of AI companies using creators’ content without consent.
- We believe creators should be able to opt in to allowing their content to be used for training purposes rather than opting out if they do not.
- Excluding GPTBot only takes effect moving forward. It doesn’t untrain existing models that have already slurped up your content to generate results based on it.
- The exclusion only applies to OpenAI, which is just one of many AI companies using content this way.
- What’s more, anything relying on robots.txt is voluntary, and not legally binding.
What we need to see is an enforceable standard that all AI companies respect, and licensing terms that are negotiated with content creators.
The AI landscape is complex and changing quickly—so recommended practices may need to evolve as we go.
But for now, unless you’re okay with OpenAI continuing to train more powerful future models on your content without consent, we recommend adding GPTBot exclusions to your site.
Here’s how to tell OpenAI to stop crawling your site
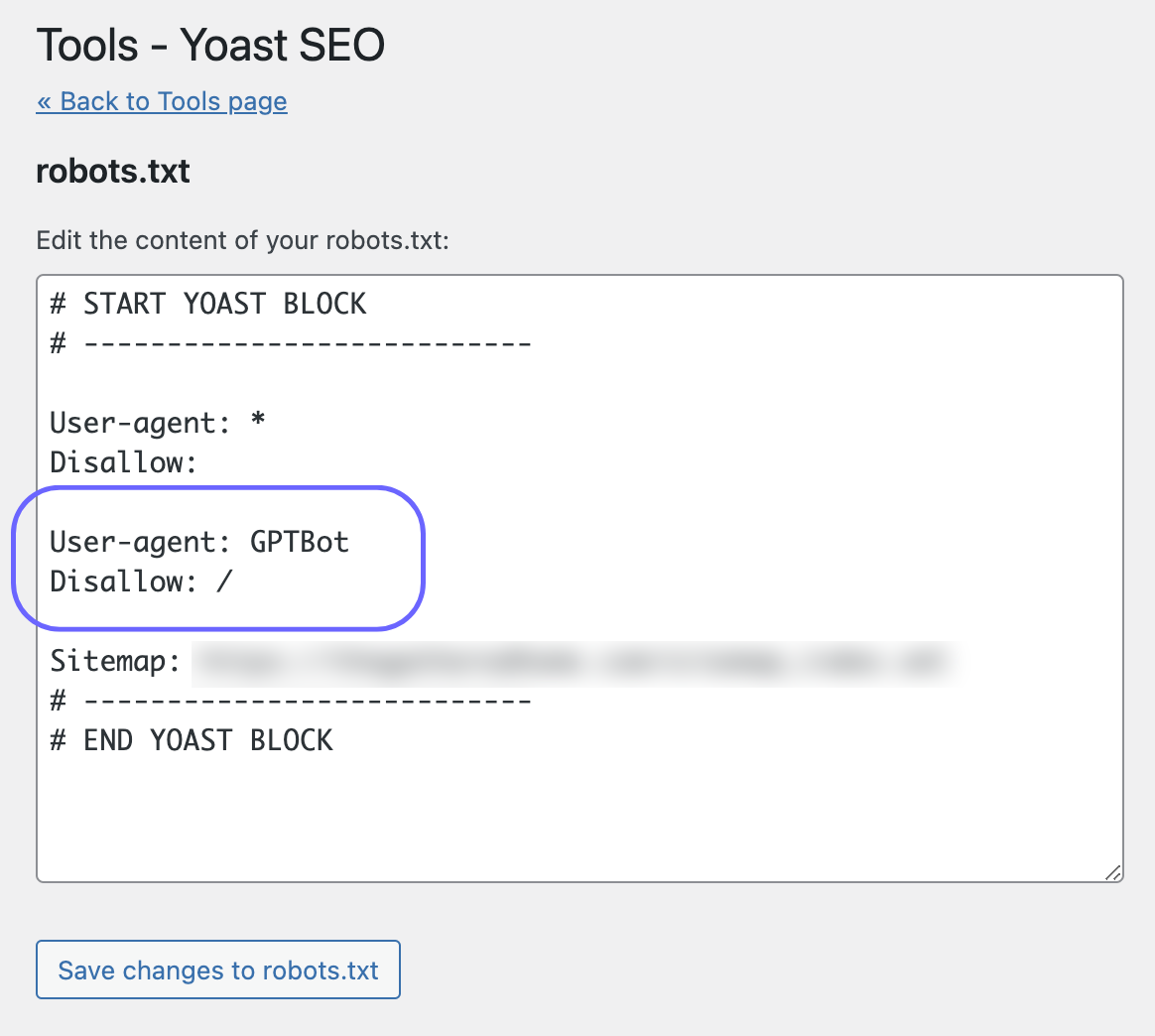
Step 1: To exclude your whole site from GPTBot, you need to add two lines to your robots.txt file.
Specifically:
User-agent: GPTBot
Disallow: /
Most sites in the Raptive network use the Yoast SEO plugin, which provides an easy UI to manage robots.txt. Just copy and paste those two lines as Yoast describes here.
As long as you don’t change anything else in your robots.txt file, this exclusion will have no effect on other crawlers, including Googlebot—so in the near term, this shouldn’t meaningfully affect search traffic. You’re merely telling the GPTBot crawler (and the GPTBot crawler alone) to stay off your site.
That said, it’s worth reevaluating this decision periodically. OpenAI feeds Bing’s generative search experience, and while Bing as a whole represents a tiny portion of search traffic today, that and many other things could change in the future.
Step 2: To be safe, it’s a good idea to use Google’s robots.txt checker once you’ve published the change.
After you’ve updated the file and cleared any caches, add /robots.txt to the end of your site’s URL in a browser window to view the updated file.
If you want to do something more involved, like exclude only parts of your site, or if you aren’t using Yoast, the process isn’t much more difficult, and the documentation from OpenAI and Yoast provides steps to do so. But if you’re uncertain, you might want to reach out to your web developer for a helping hand.
Whatever you choose, know that we’re continuing to advocate for you and for the content creator ecosystem.
Our advocacy includes ongoing conversations with OpenAI and other big tech companies about the best long-term solutions that put control back in creators’ hands. We believe creators should set the terms, and are hard at work making sure your voices have a seat at the table.
Have you signed our Open Letter to show your support for measures that protect content creators? Head here to learn more and sign.
 `
`
 `
`
 `
`