How blocking AI bots paves the way for fair compensation

The decision to block AI bots has a huge impact on your individual business and the entire digital publishing industry. We’ve spent significant time researching the topic, talking with AI labs, industry groups, and major publishers, and developing recommendations for the Raptive network.
Based on our learnings, our recommendation to block AI scraper bots is stronger than ever. It’s not a radical concept—major publishers like The New York Times, People, Inc., and Forbes all block AI crawlers.
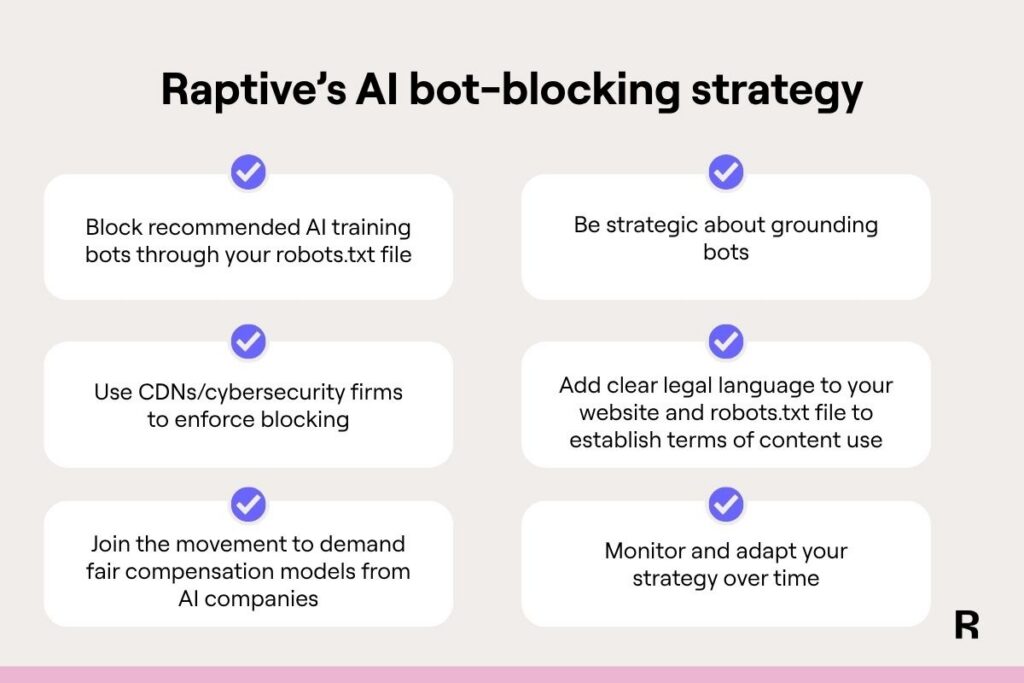
Based on our extensive data, here’s the strategy we recommend to creators and publishers:
- Block nearly every AI training bot
- Don’t optimize for AI answer bots
- Push AI companies towards fair compensation models
To understand why we’re advocating for these actions and how to implement them, let’s start with some basics.
The AI data ecosystem
When we talk about AI today, we typically mean large language models (LLMs), the technology behind tools like ChatGPT, Claude, and Gemini. The companies building the most advanced versions of these models are called “frontier labs.” For example:
- Open AI (ChatGPT)
- Anthropic (Claude)
- Google (Gemini)
These companies need massive amounts of data to train their AI systems, and your content is exactly what they’re looking for. Rather than crawl the web themselves, these companies often pay specialized third parties to do it for them.
These “scraper companies,” like Bright Data, Oxylabs, and Common Crawl, use sophisticated technology to harvest content from millions of websites, then package and sell that data to AI companies for training purposes. They’re essentially middlemen who collect your content and sell it to the highest bidder, without asking for permission or compensating you for your work.
And of course, it doesn’t stop there. In addition to frontier model companies and dedicated scrapers, there’s a whole network of businesses crawling online content. Search engines are integrating AI, startups are building specialized AI tools, research institutions are training models—the list goes on.
Understanding AI bot behavior
Not all bots are created equal, and understanding them is critical to taking strategic action. Think of them on a spectrum—some may respect your block request, others will not. That’s where you’ll need support from at least one of these types of companies that can help enforce your request:
- Content Delivery Network (CDN): Services that help quickly and reliably deliver your website’s content, like Cloudflare, Fastly, and Akamai. Many CDNs also offer security features including bot detection and blocking.
- Cybersecurity firms: Companies specializing in bot management, like Human Security and DataDome, offer more sophisticated tools to identify and block unwanted bot traffic, including AI scrapers trying to disguise themselves as legitimate visitors.
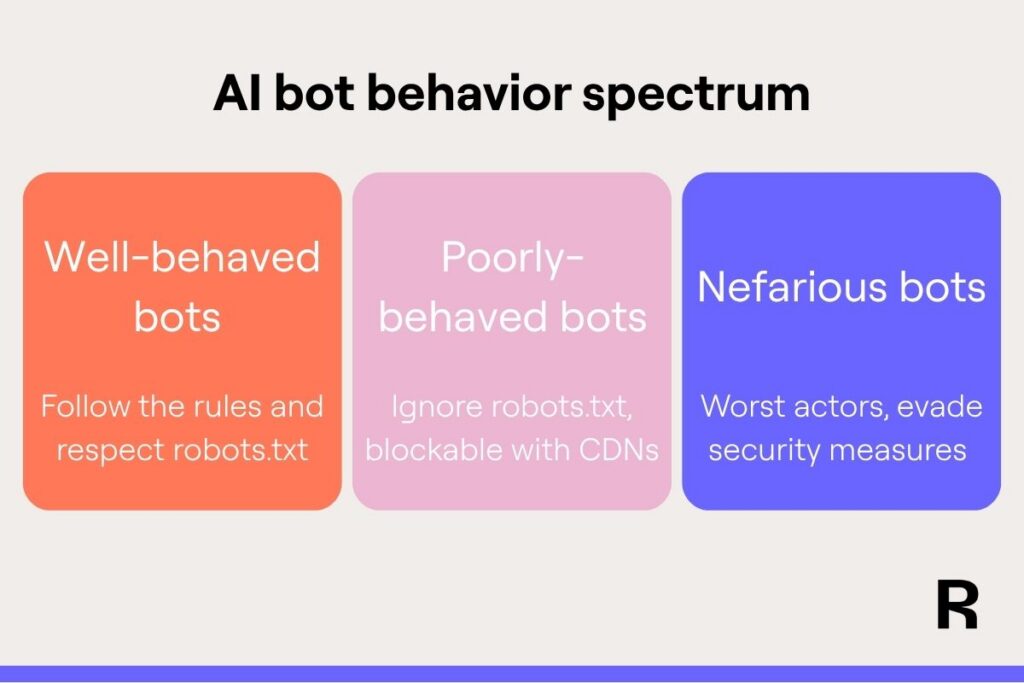
Here’s how you can think about typical bot behavior:
Well-behaved AI bots
These are mostly from the big companies like OpenAI, Anthropic, and Google. They identify themselves honestly, follow standard robots.txt rules around crawling, and generally respect publisher wishes. If you block them, they stay blocked.
Poorly-behaved but detectable bots
These crawlers don’t play by the rules, and might disguise themselves as regular browsers or ignore robots.txt. Typical methods can’t block them, but CDNs and cybersecurity companies can identify and block them through technical fingerprinting and behavior analysis.
Nefarious bots
These are the worst actors, using sophisticated techniques to evade even professional bot-detection services. They’re constantly evolving to avoid identification, and fighting them requires ongoing vigilance and advanced security measures. Even Google is suing a company for scraping its content, which shows how critical it is to work with a good CDN or cybersecurity firm.
How AI scrapers are using your data
AI bots typically use your content in two different ways: AI training and grounding.
AI training
AI training is when companies use your content to teach their AI systems. Your articles, recipes, reviews, photos, and guides all become part of the AI’s “brain.” Once trained, it doesn’t need your content anymore, because it’s already learned from it. AI training is a one-time value extraction.
Grounding
Grounding, also called Retrieval-Augmented Generation or RAG, has a different relationship to content. When an AI system is “grounded,” it retrieves current information from the web to answer questions.
If someone asks ChatGPT a question about today’s news, it might fetch recent articles to provide an accurate answer. This is closer to how search engines work, with a real-time connection between user queries and your content.
Both of these use cases raise questions about compensation, but training is particularly problematic because the AI system permanently absorbs your content’s value and you get nothing in return.
However, grounding may be giving publishers the leverage they need to demand compensation. It’s been conclusively proven that AI responses are better when they can draw on content in real time. This is a first step in shifting power back to creators and publishers.
Laying the framework for fair compensation models
What was once a pipe dream is becoming a reality, with genuine progress toward new technology and business models for AI companies to fairly compensate publishers.
At Raptive, we recently completed an alpha test with Criteo that explored new models for content compensation. This included the development of the Dynamic Content Ledger, an infrastructure designed to track and facilitate fair payment for content usage. Experiments like this help establish frameworks for what fair payment might look like.
Emerging compensation frameworks also include:
- “Pay-per-crawl” pricing models where AI companies pay publishers each time they access content, similar to how licensing works in other media industries
- “Pay-per-inference” pricing models, where AI companies would pay publishers each time their data is accessed to answer a prompt, regardless of whether it was crawled previously
- Really Simple Licensing (RSL), working to make content licensing simple and universal, so publishers can easily signal whether their content is available for AI use
We’re on the publisher steering committee for RSL and are heavily involved in industry standards work through the IAB Tech Lab, Prebid, and more. We also partner with startups like Tollbit and Prorata, as well as established leaders like Cloudflare and Microsoft.
While there’s a lot of positive action around compensation solutions, the reality is that none of them will materialize overnight. And they won’t happen at all unless creators and publishers take collective action to change the current dynamic.
What it will take for AI companies to pay publishers
AI companies are already paying for content, but the money is going to scraper companies, not the people who created and own the content. The goal is to flip this equation, making it more expensive and risky to pay scrapers than to pay publishers directly. If we manage to do that, AI companies will adopt different payment models.
Every publisher that blocks AI crawlers makes the scrapers’ job harder and drives up the cost of scraping. They have to work around more obstacles and use more sophisticated, expensive techniques.
Right now, AI systems are trained on the open web. But as more publishers block crawlers, scrapers will have limited access to premium quality content. AI companies will have to pay for good content, and those that don’t will be stuck with whatever’s left.
This creates a strong incentive to pay publishers.
There’s also legal pressure, with lawsuits from The New York Times, Penske Media, and others establishing important precedents. Regulators like the UK’s Competition and Markets Authority (CMA) are pressuring AI companies to respect content rights. As legal risks mount, the “just scrape everything” approach becomes increasingly untenable.
But the lingering question is whether AI companies will pay for content from smaller sites. We believe the answer is yes. It’s why Microsoft and Amazon are creating marketplaces to pay content creators of all sizes, and why Raptive was invited to be on the publisher steering committee of trade groups like RSL from the beginning.
How to block AI bots
You have several tools at your disposal for blocking AI bots, and we recommend using all of them.
Robots.txt
Your robots.txt file is a simple set of instructions on your website that tells search engines and bots which pages they do and don’t have your permission to crawl. This is the most basic way to signal how compliant crawlers should interact with your content. Major AI companies like OpenAI, Anthropic, and others have specific bot names you can block.
You can also add clear legal language to your robots.txt that states any crawling for AI training purposes without explicit written permission is prohibited and constitutes acceptance of licensing terms. Here’s the language The New York Times uses in their robots.txt.
If you’re using the Raptive Ads WordPress plugin, here’s how to easily block AI crawlers. If not, here are step-by-step instructions on how to manually edit your robots.txt file to request that specific AI bots not crawl your site.
To be clear, this isn’t actually “blocking” bots, it’s more “nicely requesting that bots don’t take your content.” It’s a worthwhile effort, but far from a panacea.
Meta tags
For more granular control, you can add meta tags to individual pages telling AI crawlers not to use that content for training. Only a few crawlers use this method—like Microsoft’s Bingbot—but it can be very effective in those cases.
CDN and cybersecurity solutions
For protection against bots that ignore robots.txt, you need technical enforcement. Your CDN may offer bot-blocking features, or you can invest in specialized services from companies like Human Security or DataDome.
Legal protection
Establish legal grounds for action with terms of service and content licensing language on your site. We developed Terms of Content Use that publishers can adapt to put legal protections in place. These won’t stop bad actors, but they establish a legal foundation for potential future action.
Our specific bot-blocking recommendations
After extensive research and deliberation, here’s what we recommend you do. As a reminder, we’re talking specifically about AI-related bots here, not the ”good bots” that help you maximize ad revenue.
Block all well-behaved training bots
Use robots.txt to block GPTBot, ClaudeBot, and other identified AI training crawlers. These companies have made it easy to opt out, so take them up on it.
Exception: Google-extended and Googlebot
Google-extended is Google’s robots.txt entry to block some of its AI activities. It’s separate from Googlebot, which crawls your content for search indexing.
Google claims that blocking Google-extended has no impact on search, so in theory, you can block it. However, Google hasn’t been transparent about how they actually implement these tags, so we can’t, in good conscience, make this recommendation.
Blocking Google-extended also doesn’t prevent Google from using your content in AI Overviews and other AI features that appear in search results.
Google is using its monopoly in search to extract your content for AI purposes. That’s an abuse of their dominant market position, and it’s exactly the kind of behavior that regulators and legislators need to address. Google has also said (under pressure from regulators) that it will more clearly separate its crawlers’ purposes—but that could take years to come to fruition.
Until Google changes its behavior, we don’t recommend blocking Googlebot (or Google-extended) because the cost to your search visibility is too high. But we strongly encourage you to advocate for regulatory action that forces Google to decouple search crawling from AI training.
Exception: Bingbot
Bingbot is still important for Bing search, so we recommend allowing Bingbot to crawl your site. However, tell Microsoft not to use your content for AI purposes by adding the following meta tag to your pages:
<meta name=”robots” content=”noarchive”>
Consider allowing well-behaved RAG/Grounding bots
Grounding bots like OpenAi’s OAI-SearchBot and Claude-Searchbot retrieve content in real time to answer queries, which is more like search. You might choose to allow these bots while blocking training bots, depending on your strategic priorities. We recommend blocking them, but it’s your call.
Block nefarious bots at the CDN level
Invest in bot-blocking at the technical level through your CDN. Your robots.txt isn’t enough to stop bad actors, and you’ll need enforcement.
Why you shouldn’t focus on optimizing for AI answers
While you’re making these bot-blocking decisions, you may also be wondering: “Shouldn’t I optimize my site for AI-generated answers?”
For many businesses, especially those with a physical location, getting mentioned in an AI summary could be valuable. If someone asks ChatGPT for the best Italian restaurant in Chicago and it recommends yours, that could be a new customer.
But for ad-supported online publishers, the payoff—or lack thereof—is completely different.
Your business model depends on people visiting your website, seeing ads, and engaging with your content. When an AI system summarizes your content and delivers information directly to a user, they no longer need to click through to your site, even if the citation is there. You’ve provided value, but you’ve done it in exchange for exposure, not traffic.
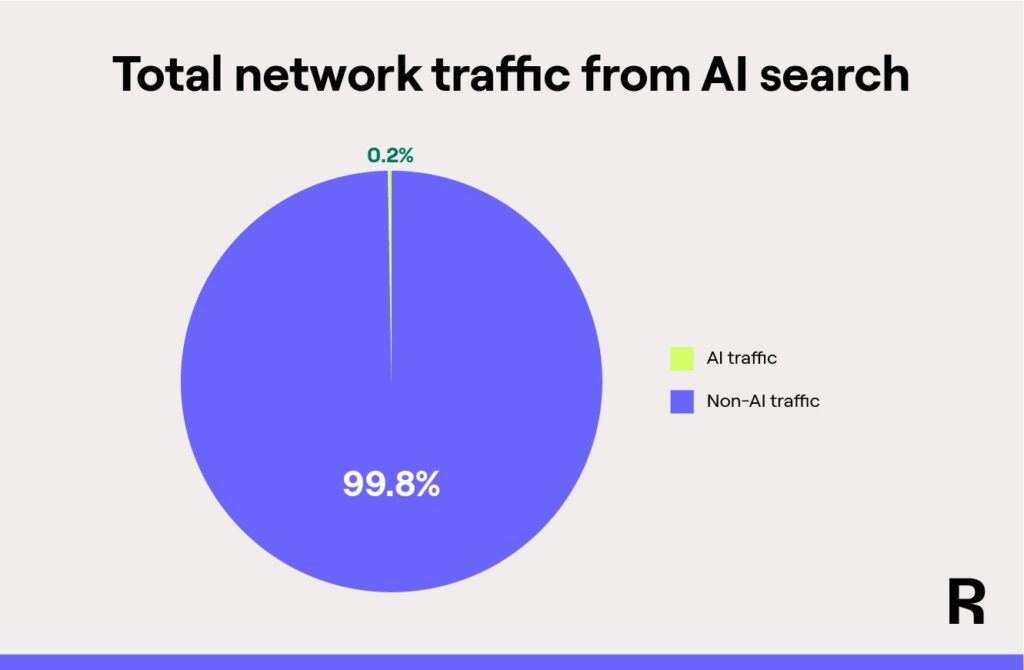
Getting mentioned by AI systems isn’t a win for online publishers, at least not the way it’s set up now. Our data shows that less than 0.2% of traffic to the Raptive network comes from ChatGPT. Rather than chasing nonexistent clicks from AI summaries, you’ll put greater pressure on AI companies to compensate you for your work by applying the bot-blocking recommendations shared here.
Take action to drive change
The AI industry is built on content created by publishers, journalists, writers, and creators. Right now, it’s continually extracting value from your work without compensating you for it. To change that reality, we need collective action.
Almost 80% of the world’s biggest news websites block AI training bots, including ABC News, Wall Street Journal, and Business Insider. Every publisher that joins this movement adds pressure to the system, but it only works if enough of us get involved.
If only a handful of publishers block AI bots, AI companies will just train on everyone else’s content. If the majority of quality content creators block AI bots, AI companies will face pressure to pay up.
We can—and should—make AI companies recognize the value of your content, but we must work together to do it.
 `
`
 `
`
 `
`